Git 的目的#
Git 是 Linux 社区无法免费使用 BitKeeper(版本管理软件)后,Linus 写的一个版本管理软件,他们对 Git 的目标是:
- 速度
- 简单的设计
- 对非线性开发模式的强力支持(允许成千上万个并行开发的分支)
- 完全分布式
- 有能力高效管理超大规模项目(例如 Linux 内核)
作为一个版本管理软件,最基础的是对特定时刻代码的保存和恢复,即快照。在一个由 Git 管理版本的软件项目中,Git 仓库(repository)是一个包含软件相关的全部源代码的目录(directory),仓库中所有 Git 相关的数据均保存在仓库根目录下的 .git 的文件夹内。
Git 的特点#
记录快照,不比较差异#
Git 在处理数据的时候,会直接将当前的状态快照,即所有由 Git 管理的文件全部存储到 Git 的底层数据库中,尝试存储的内容和上一个版本的数据无关,因此在恢复到特定版本的时候速度会更快一些。
其他大部分版本管理系统会尝试将文件的变化,即当前版本和上一个版本的差异存储到数据库中,这被称为 基于差异(delta-based)的版本控制。
同时,由于 Git 底层数据库的特点,相同的文件不会存储两份,这意味着如果每一个版本的变化很少,数据库的大小也不会增长太多。
大部分操作在本地进行#
得益于其分布式特点,本地仓库和远端仓库几乎独立而又相互联系,项目相关的所有数据都存储在本地,因此大部分操作只需要访问本地数据库,这使得这些操作“看起来瞬间完成”。
一个需要访问网络的常见情况是,你想要将本地的更改跟他人分享,即和远端数据库同步。
这意味着在没有网络连接的时候,例如在飞机上,你也可以在本地创建新的版本,只要稍后连接到网络并和远端同步即可。
Git 一般只添加数据#
大部分的 Git 操作只向底层数据库中添加数据,同时也提供了额外的工具用来尝试恢复丢失的数据,因此可以不必担心把数据弄丢。但是在使用 Git 的时候依然要注意阅读各个指令的说明,以防止各种意外情况。
获取仓库#
有两种获得仓库的方式:
- 从远端仓库进行克隆(Clone)
git clone <url> [<dir>] 会将 <url> 指定的仓库克隆到 <dir> 目录下,未指定 <dir> 时使用仓库的名字作为新文件夹名。
- 本地新建(初始化)
打开到任意目录下,git init 会将当前目录变成本地仓库,你可以在当前目录下进行提交等操作。
提交#
在 Git 中,提交 Commit 用来表示根据现有的数据创建一个版本,创建的版本也被称为“提交”。学习使用 Git,就是要学习如何更好地进行提交,以及如何管理各个提交的关系,这一小节会讲述一些基础的概念,后续的指令也会基于这些概念进行说明。
三个区域#
在一个本地仓库中,大致可以将 Git 分成三个相互关联的区域:
- 工作目录 Working Directory:是
.git目录所在的文件夹下的所有文件,不含.git目录 - 暂存区 Staging Area / 索引 Index:位于
.git/index文件,保存用于下一次提交的信息 - Git 目录 Repository:位于
.git目录中,包含了底层数据库和引用等内容

在提交修改时,通常会先将修改暂存,即将相应的修改保存到暂存区,然后再提交。此时 Git 会从暂存区读取需要添加到提交内的修改,并创建提交,这里不会直接读取硬盘上的文件。当需要恢复到某个提交的时候,可以从提交数据中恢复到工作目录(和暂存区),这个过程被称作检出(Checkout)。
所以基本的 Git 工作流为:
- 在工作区里修改文件
- 选择需要包含到下一次提交内的更改,添加到暂存区
- 提交,此时会从暂存区取出数据,并创建一个提交
文件状态#
根据文件的和 Git 系统之间的关系,一共可以分成4类:
- 未追踪 Untracked:不由 Git 管理的文件,不会被 Git 保存到数据库中,也不会在历史版本中保存。
- 已追踪:由 Git 管理的文件,更进一步地细分为如下三种状态
- 未修改 Unmodified:与上一个提交相比,文件的内容(或者属性等)未被修改。
- 已修改 Modified:与上一个提交相比,文件被修改过
- 已暂存 Staged:已修改/未追踪的文件通过
git add等方式添加到了暂存区(索引)中
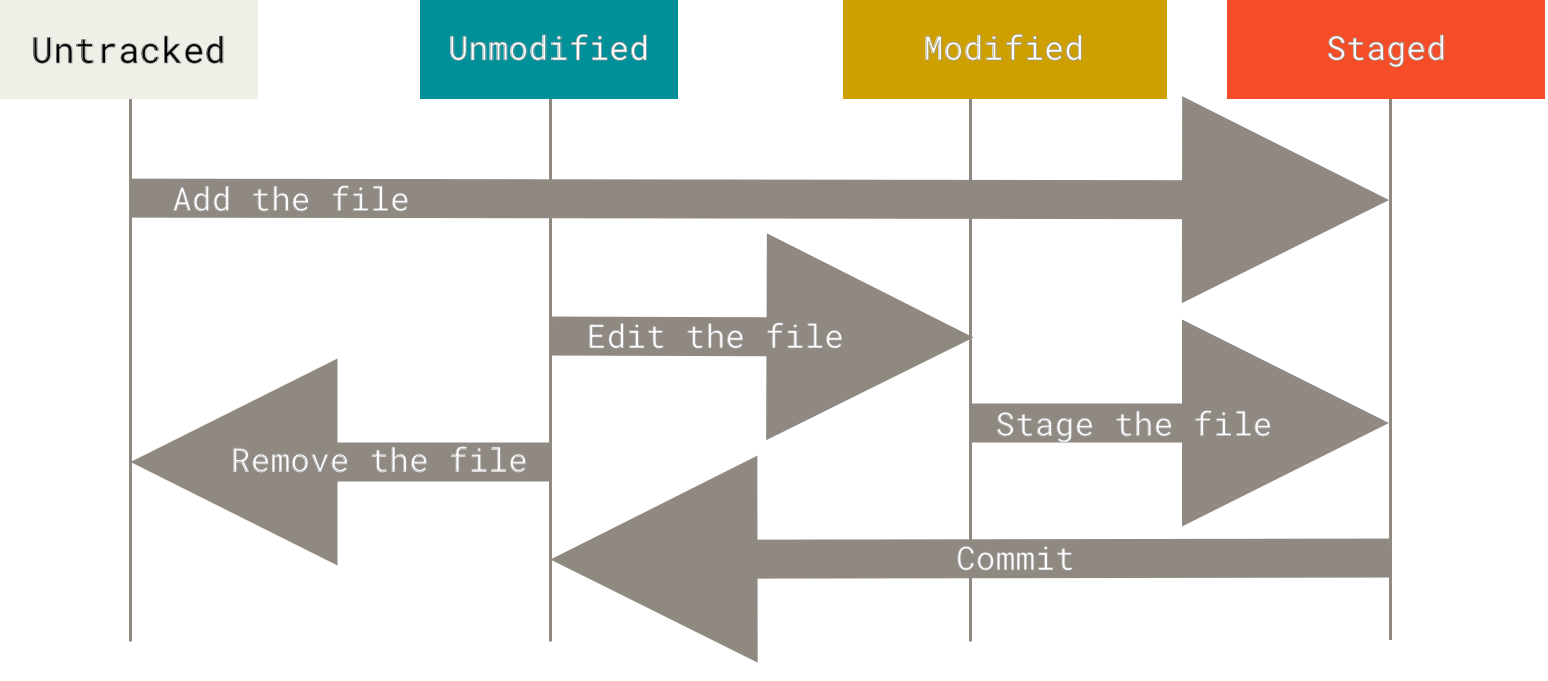
Git 提供了 git status 来查看文件状态。
简单工作流#
首先,假设我们已经在一个初始化好的仓库内,新建了一个文件 main.c 并编写了一些内容,现在文件的状态是未追踪。为了让这个文件被 Git 管理,我们需要添加到 Git 中:git add main.c 或者更常用的 git add . ,这样文件就变成了已暂存。
然后我们进行提交 git commit -m <msg> ,在提交后文件就会变成未修改,其中 <msg> 作为这个提交的说明,可以是任何内容,但是建议使用 约定式提交
,保证语义清晰。
随后如果对这个文件进行了编辑,文件就会变成已编辑,此时只要按照上面的 git add、git commit 流程即可将修改添加到下一个提交中。
如果想要查看历史提交,可以使用 git log --graph --oneline --all 后面三个参数可以自行查阅手册,在输入这条指令后,使用 J K 或者方向键上下移动,使用 Q 退出。
.gitignore#
上文使用 git add . 的时候会将当前目录中的所有文件全部添加进去,但是在实践中会有一些文件不适合由 Git 管理,例如 C 程序的编译输出、中间产物,或者是包含密钥的文件,或者是平台特定的文件,此时我们将这些文件添加到 .gitignore 文件中,这样在 git add 的时候就会自动忽略,详细语法请看 Gitignore Docs
,如下是一个示例。
.vscode
public
resources
.hugo_build.lock
Git Graph#
通过上面两段,你应该了解了 Git 是如何进行提交的,现在讲述提交之间的关系。
提交历史#

上图是进行了 4 次提交的本地 Git 仓库。四个圆形表示四次提交,为简化说明,用字母指代每个提交,实际工作中主要使用每个提交的 SHA 的前 7 个字符来表示一个提交。圆形间的箭头用来表示提交间的父子关系,你可以想象成指针,例如 A <- B 表示了 A 是 B 的父提交,即 B 是基于 A 的一个提交。
上方的两个方块表示引用,也可以想象成指针,其中 main 是主分支名,HEAD 是一个特殊的引用,标示着当前的工作目录是基于哪个提交的,在进行新的提交时会把 HEAD 指向的提交作为父提交,同时会将 main 引用的提交修改为最新的提交,由于 HEAD 引用的是一个引用,也会自动修改最终指向的提交。
想要指定某一个提交,不仅可以通过 SHA 的方式“绝对指定”,还可以通过它的子提交“相对指定”。例如,我想要指定上一个提交,可以使用 HEAD^ HEAD@{1} HEAD~1 表示,详细可以看 gitrevisions
简单工作流的补充#
我们在仓库里进行了几次提交,然后发现上一次的提交有问题,想要修改他,有两种方法:
git commit --amend
这条指令会将当前暂存的修改添加到上一个提交中,提交的 SHA 也会随之变化。
git reset [--soft | --mixed | --hard] <commit>
这条指令有三个常用的参数:
--soft:只移动相关的引用,在这里指的是 main,这样相当于取消了commit操作--mixed:将暂存区重置到指定的提交的状态,相当于取消了add操作--hard:将暂存区和工作目录重置到指定的提交的状态,这会删除你做的任何修改,相当于取消了编辑操作
分支#
在开发过程中,有时需要一个隔离的工作环境,比如为了不同的目的而使用不同的分支( main dev),或者为了特定需求单开一个分支( fix-some-bugs imple-some-feat)。Git 通过一个绝妙的方式支持了分支功能,减少了低效的文件复制操作。
先让我们回到这张图,图中的 main 就是一个分支名,在 Git 中,这被用作默认主分支名(过去是 master)。HEAD 指针在这里还起到了指示当前分支的作用。如果还想添加一个新分支 git branch dev,就会变成下图。

可以看出来,新建分支的本质是新建了一个引用,不存在任何复制过程。此时我们可以用 git checkout <branch> 切换分支,本质是修改了 HEAD 引用,请注意,这也会修改工作目录中的文件。下面我们在不同的分支上进行几次提交。
git commit

git checkout dev

git commit

现在让我们重新考虑一下上面说的父子提交。在 Git 中,一个提交的子提交可以有多个,我们可以称在这个提交分叉了。在图中表现为 D 提交有 E F 两个子提交,整个提交记录在 D 处分叉了。
如果在这里,我们希望将 dev 分支的修改合并到 main 分支中,我们可以使用不同的方法,这些方法各有利弊,只要根据情况选择最合适的方法即可。
merge 合并#
会新建一个提交,包含了来自两个分支的修改,然后提交到其中一个分支

想要从 dev 分支合并到 main 分支,首先需要检出 main 分支 git checkout main,然后使用 git merge dev。
合并中,Git 会添加一个独特的引用 MERGE_HEAD,这标记了需要被合并的分支,并且在成功合并后删除。
在合并时,如果两个分支间有冲突的修改,即在同一处进行了修改,Git 就会停下来,等待你去解决相应的冲突,此时 MERGE_HEAD 不会被删除。冲突通常以这样的方式在原文件中展示出来:
<<<<<<< HEAD
## content changed in main branch
=======
## content changed in dev branch
>>>>>>> dev
其中的 <<<<<<<、=======、>>>>>>> 表示在这里存在冲突,上半部分是当前分支(HEAD)的版本,下半部分是准备合并的部分(dev)的版本,假设我们手动解决了冲突,把冲突的部分改写了:
## content changed for fixing conflict
然后使用 git add 来向 Git 说明你已经解决了冲突。在所有冲突解决完后,使用 git commit 进行提交。如果不想继续处理冲突,可以取消合并 git merge --abort,相应的操作会还原。
rebase 合并#
会将一个分支的全部内容移动到另一个分支的后面,即改变当前分支的“基础”,会修改相应提交的 SHA

想要以 rebase 方式从 dev 分支合并到 main 分支,需要先将 dev 分支的提交移动到 main 分支后方 git rebase main,然后检出 main 分支 git checkout main,使用常规的 merge 合并即可 git merge dev,可以添加 --ff-only 参数,要求 Git 只进行 Fast Forward。
Fast Forward 表示可以不用创建一个新的 merge 提交的情况,即当前提交为要合并提交的父提交的情况,这种情况很常见,此时不需要创建新的提交,只需要移动 HEAD 和对应的分支引用。
另外,git rebase -i 提供了一个强大的互动式变基,可以自行研究。
squash 合并#
会将 dev 分支上有的,而 main 上没有的修改组合成一个提交添加到 main 分支上

为了减少误解,在这里我们先再向 dev 分支进行一次提交,可以看到在 main 上多出来一个 H 提交,在这个提交里包含了 dev 分支有而 main 分支没有的修改,是 F、G 提交的组合。
我们使用 git merge --squash dev 进行 squash 合并,这一步会将 dev 分支独有的修改添加到暂存区和工作目录内,就像普通的合并一样,但是不会提交,需要我们手动进行提交 git commit。
本地与远程#
上面几节内容中,应当已经掌握了本地 Git 的大多数操作,现在我们谈论如何在这个基础上和其他人协作。
为了进行协作,需要在本地的 Git 仓库中添加相应的远程仓库,这里的远程指的是在其他地方的仓库,也可以是本地不同位置的仓库。
我们可以通过 git remote 管理远程仓库,远程仓库通常命名为 origin,此外上游仓库 upstream 也很常见,常用于从其他项目 fork 出来的分支上使用。
在协作时通常先从远程仓库同步分支 git fetch,通常分支名为 origin/<branch-name>,这些分支是本地存储的远程分支,称为远程跟踪分支。远程跟踪分支由 Git 进行管理,你无法在本地修改,但是只要和远程仓库进行了连接,远程跟踪分支就会和实际的远程仓库分支进行同步,你可以把他们看作书签,标记这最后一次连接时,远程仓库分支的状态。
然后根据远程分支检出相应的本地分支 git checkout <branch>,Git 提供了多种方法,这是最简单的一种,只要保证本地没有重名分支,而且 <branch> 和远程分支名称相同,就会自动检出相应的分支并设置上游分支。
上游分支是 Git 提供的将本地分支和远程分支联系在一起的方法,更具体来说是分支的 remote 和 merge 属性,这两个属性一起指定了本地分支对应的远程分支,此时远程分支称为上游分支,本地分支称为追踪分支,在执行需要和远程同步的指令时会自动选择本地分支的上游分支。
然后在本地分支上进行提交 git commit,然后将这个提交推送到远程仓库 git push。推送过程实际上是使用本地引用更新远程引用,同时发送所需的对象,在更新的过程中,本地和远程会进行相应的检查。通常情况下,远程仓库只接收可以 Fast Forward 的提交,这样在更新的过程中不会丢失任何数据,但如果有相应的权限,也可以绕过检查,例如 git push -f (当和他人共同在一个分支上开发的时候,不要在不交流的情况下使用这个指令,这有可能导致他人的修改丢失)
有的时候,git push 会报错,这有可能是因为有其他人同步了提交到同一个远程分支。这个时候就先要拉取数据 git pull,默认情况下会尝试进行 merge,也可以通过配置的方式修改成 rebase 等。或者你也可以只获取数据 git pull,然后通过各种方式与 origin/<branch> 同步。在本地解决冲突后可以再次尝试推送。
工作流#
根据上面的讲解,我们知道,如果许多开发者同时在一个分支提交的话,会造成大量的冲突,也会使提交记录会变得混乱。工作流正是为了解决这个问题,下面只讲解比较常见的 gitflow 工作流。
gitflow 工作流有两个长期分支:main 分支作为主分支,dev 分支作为开发分支。主分支为对外发布的分支,任何时候从这个分支获取的都是稳定版本;开发分支用于日常开发,存放最新的开发版,可能会出现不稳定的情况。
此外还有一些短期分支:
- 功能分支:用于开发特定功能,从 dev 分支分叉,合并到 dev 分支
- 补丁分支:用于修复特定 bug,普通 bug 从 dev 到 dev,紧急 bug 从 main 到 main 和 dev
- 发布分支:从 dev 分叉,用于处理发布相关的问题,比如文档、bug 等,合并到 main 和 dev
更多参见:
- https://www.ruanyifeng.com/blog/2015/12/git-workflow.html
- https://github.com/xirong/my-git/blob/master/git-workflow-tutorial.md
- https://docs.github.com/en/get-started/getting-started-with-git/git-workflows
- https://github.com/geeeeeeeeek/git-recipes/wiki/3.5-%E5%B8%B8%E8%A7%81%E5%B7%A5%E4%BD%9C%E6%B5%81%E6%AF%94%E8%BE%83
其他#
子模块#
通常我们在项目里会遇到需要包含其他项目的情况,此时就需要子模块,它允许将另一个项目克隆到自己的项目中,同时保持提交的独立
对于一个克隆下来的项目,可以通过运行以下命令将子模块克隆:
git submodule initgit submodule update
也可以在克隆时添加参数 --recurse-submodules ,在克隆时会自动初始化子模块
log/config#
有一些常用指令可以用来查看日志、提交记录等内容
git log:查看提交记录,推荐指令git log --all --oneline --graphgit reflog:(ref/log)查看日志,包含相应的提交哈希值,如果代码丢了可以尝试用这个方法找回git config:Git 配置
相关文档#
- ProGit(中文):https://git-scm.com/book/zh/v2
- Git 官方文档:https://git-scm.com/docs
- git cheat-sheet:https://training.github.com/downloads/zh_CN/github-git-cheat-sheet
- 互动式 cheat-sheet:https://ndpsoftware.com/git-cheatsheet.html
- git 简明指南:https://rogerdudler.github.io/git-guide/index.zh.html
